Fast Web Scraping With ReactPHP
Video
Web scraping relies on the HTML structure of the page, and thus cannot be completely stable. When HTML structure changes the scraper may become broken. Keep this in mind when reading this article. At the moment when you are reading this, css-selectors used here may become outdated.
![]()
Almost every PHP developer has ever scraped some data from the Web. Often we need some data, which is available only on some website and we want to pull this data and save it somewhere. It looks like we open a browser, walk through the links and copy data that we need. But the same thing can be automated via script. In this tutorial, I will show you the way how you can increase the speed of you scraper making requests asynchronously.
The Task
We are going to create a simple web scraper for parsing movie information from IMDB movie page:
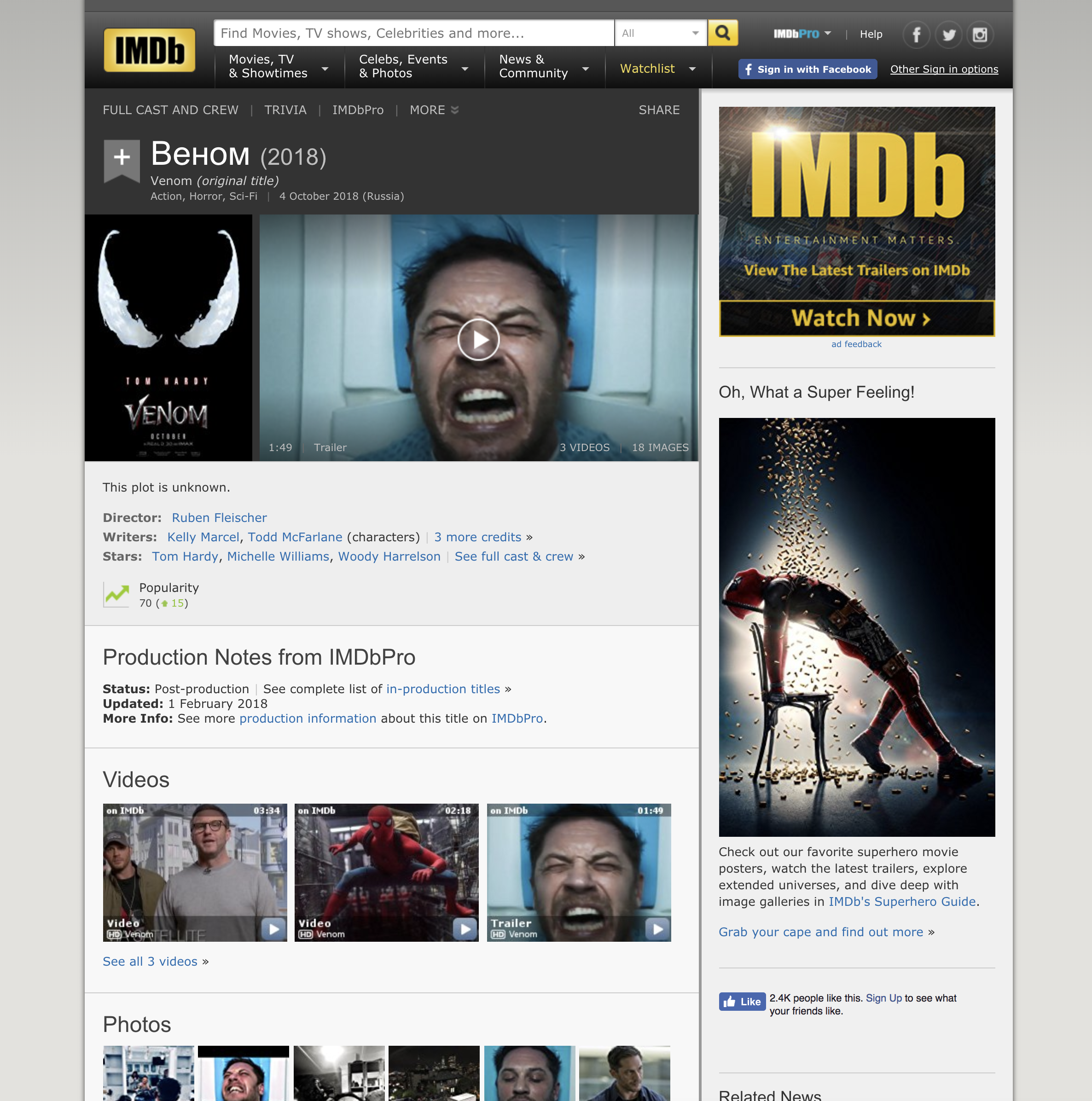
Here is an example of the Venom movie page. We are going to request this page to get:
- title
- description
- release date
- genres
IMDB doesn’t provide any public API, so if we need this kind of information we have to scrape it from the site.
Why should we use ReactPHP and make requests asynchronously? The short answer is speed. Let’s say that we want to scrape all movies from the Coming Soon page: 12 pages, a page for each month of the upcoming year. Each page has approximately 20 movies. So in common, we are going to make 240 requests. Making these requests one after another can take some time…
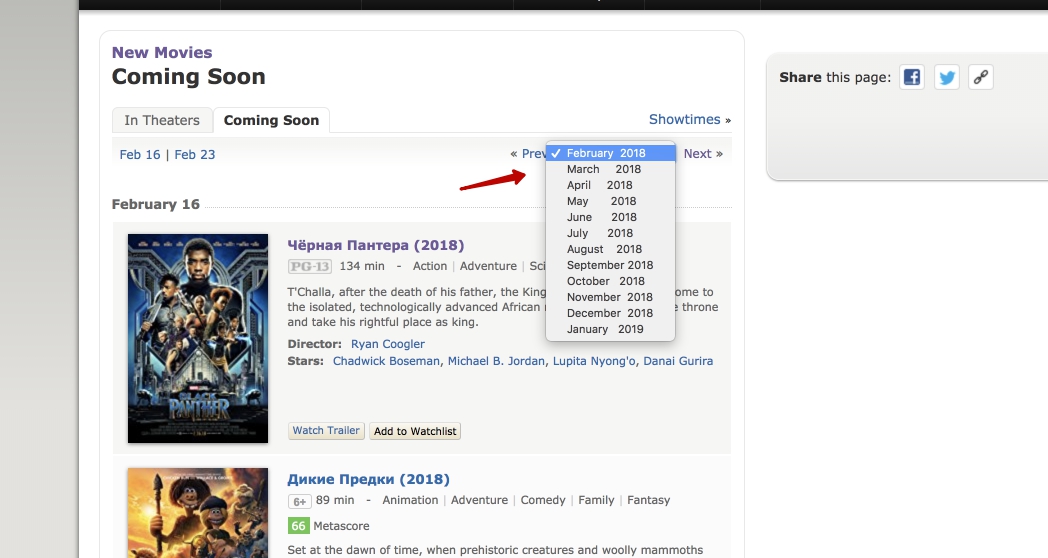
And now imagine that we can run these requests concurrently. In this way, the scraper is going to be significantly fast. Let’s try it.
Set Up
Before we start writing the scraper we need to download the required dependencies via composer.
We are going to use asynchronous HTTP client called buzz-react a library written by Christian Lück. It is a simple PSR-7 HTTP client for ReactPHP ecosystem.
composer require clue/buzz-reactFor traversing the DOM I’m going to use Symfony DomCrawler Component:
composer require symfony/dom-crawlerCSS-selector for DomCrawler allows to use jQuery-like selectors to traverse:
composer require symfony/css-selectorNow, we can start coding. This is our start:
<?php
use Clue\React\Buzz\Browser;
$loop = React\EventLoop\Factory::create();
$client = new Browser($loop);
// ...We create an instance of the event loop and HTTP client. Next step is making requests.
Making Request
Public interface of the client’s main Clue\React\Buzz\Browser class is very straightforward. It has a set of methods named after HTTP verbs: get(), post(), put() and so on. Each method returns a promise. In our case to request a page we can use get($url, $headers = []) method:
<?php
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
echo $response->getBody() . PHP_EOL;
});The code above simply outputs the requested page on the screen. When a response is received the promise fulfills with an instance of Psr\Http\Message\ResponseInterface. So, we can handle the response inside a callback and then return processed data as a resolution value from the promise.
Unlike ReactPHP HTTPClient,
clue/buzz-reactbuffers the response and fulfills the promise once the whole response is received. Actually, it is a default behavior and you can change it if you need streaming responses.
So, as you can see, the whole process of scraping is very simple:
- Make a request and receive the promise.
- Add a fulfillment handler to the promise.
- Inside the handler traverse the response and parse the required data.
- If needed repeat from step 1.
Traversing DOM
The page that we need doesn’t require any authorization. If we look at the source of the page, we can see that all data that we need is already available in HTML. The task is very simple: no authorization, form submissions or AJAX-calls. Sometimes analysis of the target site takes several times more time than writing the scraper, but not this time.
After we have received the response we are ready to start traversing the DOM. And here Symfony DomCrawler comes into play. To start extracting information we need to create an instance of the Crawler. Its constructor accepts HTML string:
<?php
use \Symfony\Component\DomCrawler\Crawler;
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
});Inside the fulfillment handler, we create an instance of the Crawler and pass it a response cast to a string. Now, we can start using jQuery-like selectors to extract the required data from HTML.
Title
The title can be taken from the h1 tag:
<?php
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
$title = trim($crawler->filter('h1')->text());
});Method filter() is used to find an element in the DOM. Then we extract text from this element. This line in jQuery looks very similar:
var title = $('h1').text();Genres And Description
Genres are received as text contents of the corresponding links.
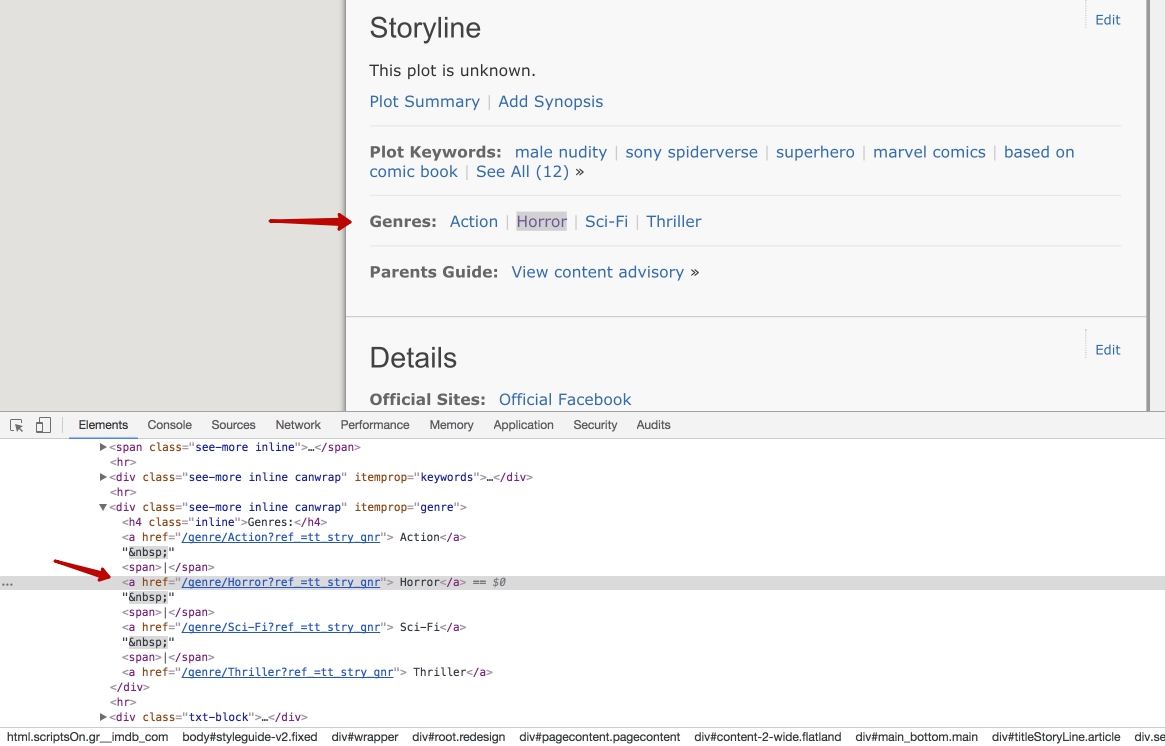
<?php
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
$title = trim($crawler->filter('h1')->text());
$genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']);
$description = trim($crawler->filter('[itemprop="description"]')->text());
});Method extract() is used to extract attribute and/or node values from the list of nodes. Here in ->extract(['_text']) statement special attribute _text represents a node value. The description is also taken as a text value from the appropriate tag
Release Date
Things become a little tricky with a release date:
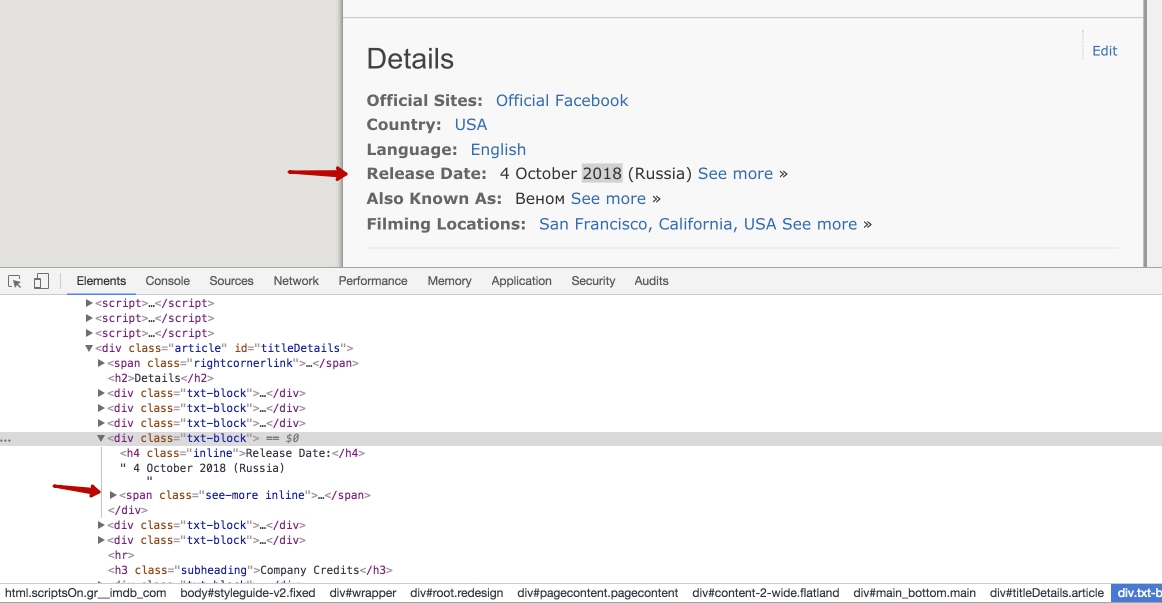
As you can see it is inside <div> tag, but we cannot simply extract the text from it. In this case, the release date will be Release Date: 16 February 2018 (USA) See more ». And this is not what we need. Before extracting the text from this DOM element we need to remove all tags inside of it:
<?php
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
// ...
$crawler->filter('#titleDetails .txt-block')->each(function (Crawler $crawler) {
foreach ($crawler->children() as $node) {
$node->parentNode->removeChild($node);
}
});
$releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text());
});Here we select all <div> tags from the Details section. Then, we loop through them and remove all child tags. This code makes our <div>s free from all inner tags. To get a release date we select the fourth (at index 3) element and grab its text (now free from other tags).
The last step is to collect all this data into an array and resolve the promise with it:
<?php
// ...
$client->get('http://www.imdb.com/title/tt1270797/')
->then(function(\Psr\Http\Message\ResponseInterface $response) {
$crawler = new Crawler((string) $response->getBody());
$title = trim($crawler->filter('h1')->text());
$genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']);
$description = trim($crawler->filter('[itemprop="description"]')->text());
$crawler->filter('#titleDetails .txt-block')->each(function (Crawler $crawler) {
foreach ($crawler->children() as $node) {
$node->parentNode->removeChild($node);
}
});
$releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text());
return [
'title' => $title,
'genres' => $genres,
'description' => $description,
'release_date' => $releaseDate,
];
});Collect The Data And Continue Synchronously
Now, its time to put all pieces together. The request logic can be extracted into a function (or class), so we could provide different URLs to it. Let’s extract Scraper class:
<?php
class Scraper
{
/**
* @var Browser
*/
private $client;
/**
* @var array
*/
private $scraped = [];
public function __construct(Browser $client)
{
$this->client = $client;
}
public function scrape(array $urls = [])
{
$this->scraped = [];
foreach ($urls as $url) {
$this->client->get($url)->then(
function (\Psr\Http\Message\ResponseInterface $response) {
$this->scraped[] = $this->extractFromHtml((string) $response->getBody());
});
}
}
public function extractFromHtml($html)
{
$crawler = new Crawler($html);
$title = trim($crawler->filter('h1')->text());
$genres = $crawler->filter('[itemprop="genre"] a')->extract(['_text']);
$description = trim($crawler->filter('[itemprop="description"]')->text());
$crawler->filter('#titleDetails .txt-block')->each(
function (Crawler $crawler) {
foreach ($crawler->children() as $node) {
$node->parentNode->removeChild($node);
}
}
);
$releaseDate = trim($crawler->filter('#titleDetails .txt-block')->eq(3)->text());
return [
'title' => $title,
'genres' => $genres,
'description' => $description,
'release_date' => $releaseDate,
];
}
public function getMovieData()
{
return $this->scraped;
}
}It accepts an instance of the Browser as a constructor dependency. The public interface is very simple and consists of two methods: scrape(array $urls)) and getMovieData(). The first one does the job: runs the requests and traverses the DOM. And the seconds one is just to receive the results when the job is done.
Now, we can try it in action. Let’s try to asynchronously scrape two movies:
<?php
// ...
$loop = React\EventLoop\Factory::create();
$client = new Browser($loop);
$scraper = new Scraper($client);
$scraper->scrape([
'http://www.imdb.com/title/tt1270797/',
'http://www.imdb.com/title/tt2527336/'
]);
$loop->run();
print_r($scraper->getMovieData());In the snippet above we create a scraper and provide an array of two URLs for scraping. Then we run an event loop. It runs until it has something to do (until our requests are done and we have scrapped everything we need). As a result instead of waiting for all requests in total, we wait for the slowest one. The output will be the following:
Array
(
[0] => Array
(
[title] => Venom (2018)
[genres] => Array
(
[0] => Action
[1] => Horror
[2] => Sci-Fi
[3] => Thriller
)
[description] => This plot is unknown.
[release_date] => 4 October 2018 (Russia)
)
[1] => Array
(
[title] => Star Wars: Episode VIII - The Last Jedi (2017)
[genres] => Array
(
[0] => Action
[1] => Adventure
[2] => Fantasy
[3] => Sci-Fi
)
[description] => Rey develops her newly discovered abilities with the guidance of Luke Skywalker, who is unsettled by the strength of her powers. Meanwhile, the Resistance prepares for battle with the First Order.
[release_date] => 14 December 2017 (Russia)
)
)You can continue with these results as you like: store them to different files or save into a database. In this tutorial, the main idea was to show to make asynchronous requests and parse responses.
Adding Timeout
Our scraper can be also improved by adding some timeout. What if the slowest request becomes too slow? Instead of waiting for it, we can provide a timeout and cancel all slow requests. To implement request cancellation we will use event loop timers. The idea is the following:
- Get the request promise.
- Create a timer.
- When the timer is out cancel the promise.
Now, we need an instance of the event loop inside our Scraper. Let’s provide it via constructor:
<?php
class Scraper
{
// ...
/**
* @var \React\EventLoop\LoopInterface
*/
private $loop;
public function __construct(Browser $client, LoopInterface $loop)
{
$this->client = $client;
$this->loop = $loop;
}
}Then we can improve scrape() method and add optional parameter $timeout:
<?php
class Scraper
{
// ...
public function scrape(array $urls = [], $timeout = 5)
{
$this->scraped = [];
foreach ($urls as $url) {
$promise = $this->client->get($url)->then(
function (\Psr\Http\Message\ResponseInterface $response) {
$this->scraped[] = $this->extractFromHtml((string) $response->getBody());
});
$this->loop->addTimer($timeout, function() use ($promise) {
$promise->cancel();
});
}
}
}If there is no provided $timeout we use default 5 seconds. When the timer is out it tries to cancel the provided promise. In this case, all requests that last longer than 5 seconds will be cancelled. If the promise is already settled (the request is done) method cancel() has no effect.
For example, if we don’t want to wait longer than 3 seconds the client code is the following:
<?php
// ...
$scraper->scrape([
'http://www.imdb.com/title/tt1270797/',
'http://www.imdb.com/title/tt2527336/',
], 3);A Note on Web Scraping: some sites don’t like being scrapped. Often scraping data for personal use is generally OK. But you should always scrap nicely. Try to avoid making hundreds of concurrent requests from one IP. The site may don’t like it and may block your scraper. To avoid this and improve your scraper read the next article about throttling requests.
You can find examples from this article on GitHub.
This article is a part of the ReactPHP Series.
Learning Event-Driven PHP With ReactPHP
The book about asynchronous PHP that you NEED!
A complete guide to writing asynchronous applications with ReactPHP. Discover event-driven architecture and non-blocking I/O with PHP!
Minimum price: 5.99$